 Find: A Tool for Transitive Pattern Recognition
Find: A Tool for Transitive Pattern Recognition
Find: A Tool for Transitive Pattern Recognition
Find: A Tool for Transitive Pattern Recognition
Find is a static analysis tool in the Toolsuite. Find supports the identification of date-sensitive objects through a simple transitive relation. Date-sensitive patterns are initially specified which are common across the application. The atoms (groups of characters, surrounded by white space) in the code that match each pattern are then either accepted or rejected. Acceptance or rejection can be selected in either local file or global scope. Once the initial atoms are selected, the transitive relation is invoked, which identifies more candidates for date-sensitive objects. By selectively pruning objects that are not date-sensitive, closure on the date-sensitive objects in the application can be reached. Output from Find is then exported to the remaining tools to specify interesting regions for testing. Because the transitive relation is a simple heuristic, namely objects on the same line, Find is language independent, and well-adapted to pointer-based languages like C or C++. Other languages, like Perl or Tcl are also excellent candidates for analysis through Find.
One of Find's principle applications is to analyze and delineate date-sensitive code. The simplest form of a date pattern might be mmddyy (two numbers each for month, day and year such as 032697). A default seed file is provided for this application, which includes the most frequent formats for encoding dates.
The tool applies the patterns to atoms (groups of characters, surrounded by white space) in the code, which are all words except those included in a stop list. The stop list is user definable and typically includes keywords of the language being analyzed. As the atoms satisfy the patterns, they are highlighted in red as candidates.
The candidates are inspected for relevance to the feature code being delineated. Based upon this determination, the atoms matching the patterns in the seed file are accepted or rejected in either file or global scope. Upon completion of this task, the heuristic that generates further candidates is applied. As currently implemented, new candidates are those atoms on the same line but not excluded by the stop list.
Iteration through inspection of candidates, determination of their relevance, and generation of new candidates is performed until no further relevant new candidates are generated. At this point the process ceases.
Find requires close user-interaction with and intuition about the program being analyzed. Without this judgement, static analysis of the type outlined above does not converge. With appropriate pruning of the dependencies among atoms in the code, static analysis becomes a useful tool for isolating feature code in large programs.
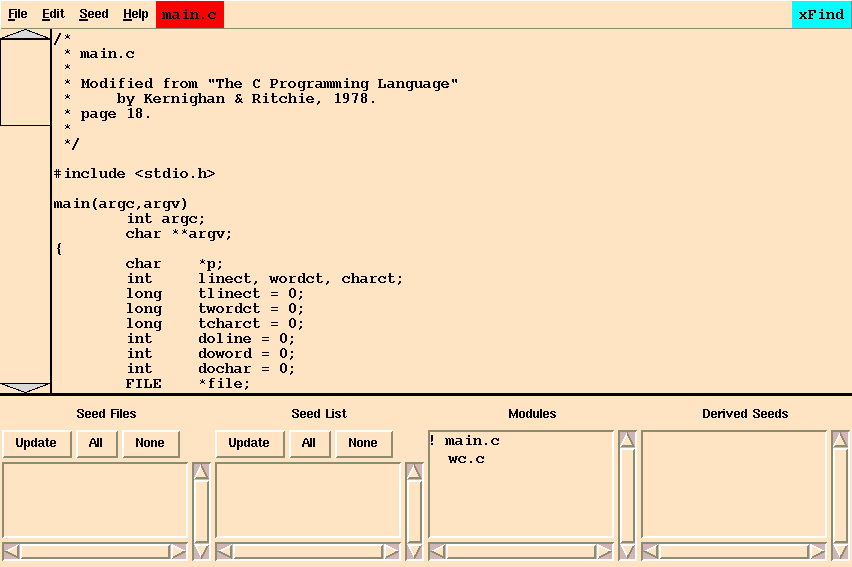
The wordcount program has the ability to count either characters, words or lines depending on the command line options. Each of these abilities is deemed a feature. This tutorial will find and demark all code that implements the word counting feature. In another application the feature might just as easily be date sensitive. Start the tutorial by typing:
prompt:> xfind main.c wc.cat the command-line prompt. The resulting display will appear as in Figure 15-1.
 |
Other entries in the ``Edit'' menu include:
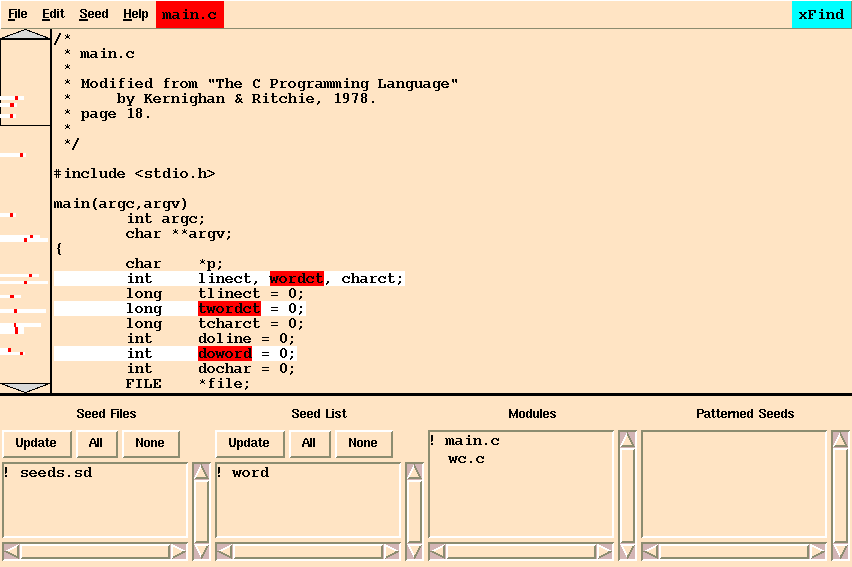
The program may be seeded with initial patterns to be matched either from a seed file or interactively from the program display area. Selecting seeds interactively is accomplished by sweeping out an atom with the left mouse button and invoking either the ``All'' or ``File'' option in the ``Seed'' menu depending on whether the selected atom is in either global or file scope. Two seed files are included in the tutorial as shown in Figure 15-2. The file seeds.sd is used in this tutorial, whereas dates.sd is displayed to provide a more illustrative example of a seed file. Patterns can be changed or inserted one per line in the seed files, which must have the extension .sd. Patterns may be excluded beyond the default list by populating the excludeSeed region of the file. These patterns should be entered between the curly braces, one pattern per line.
 |
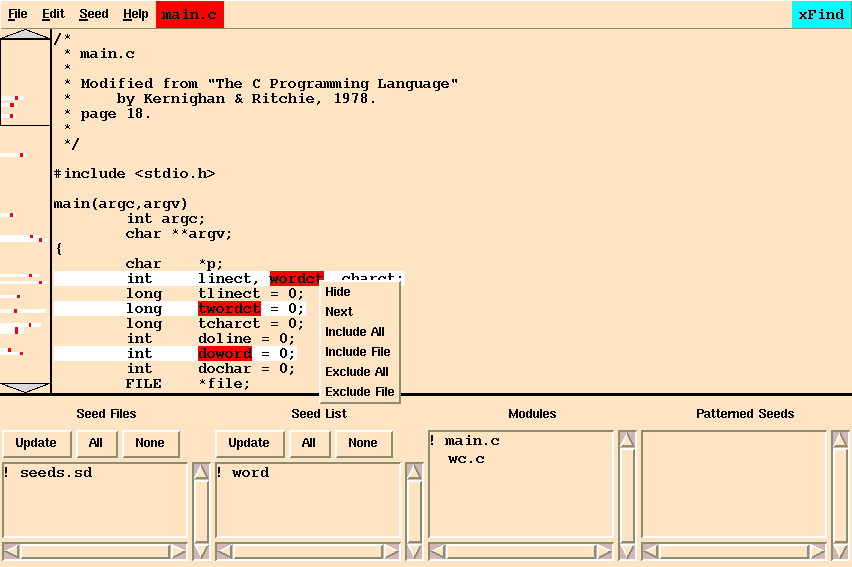
Classify each of the candidates highlighted in red according to whether it is included or excluded in file or global scope. Atoms that are defined as static or automatic variables should be selected at file scope while those defined as global should be selected at global scope. Click the left mouse button on the red highlighted wordct at the beginning of main.c. The pop-up menu in Figure 15-4 appears. Move the mouse down to select ``Include File''. This will insert wordct into the ``Patterned Seeds'' control box. Other entries in the pop-up menu include:
 |
Click twordct and move the mouse down to select ``Include File''. Repeat this for doword. These atoms will appear in the ``Patterned Seeds'' control box and all other instances of the atom will change color to either green or yellow depending on whether they were included or excluded from further consideration. Atoms that the user does not wish to explicitly exclude may be left alone; they will not appear at the next level in the relation. For example, the candidates which match the ``word'' pattern in module wc.c should be ignored, as should all words within comments.
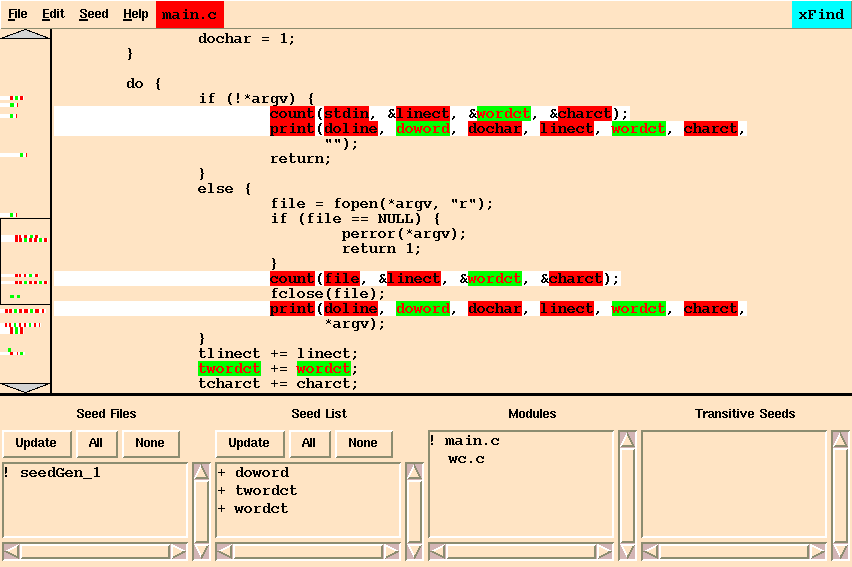
Now invoke the ``New Level'' entry in the ``Seed'' menu, which computes the next set of candidate atoms and updates the Find window. Scroll down until you see what is displayed in Figure 15-5.
 |
the ``Seed'' menu |
Other entries in the ``Seed'' menu include:
Select the wc.c module and observe that, ``count'' is a candidate atom. It is known from the previous level that the third argument of ``count'' is connected with the word counting feature, therefore ``p_nw'' should be included in file scope. Everything else on that line should be excluded at the file level. Select ``Seed/New Level'' to generate new candidates. This action leads to one new candidate atom, ``nw'', which should be included in file scope and ``Seed/New Level'' selected. At this point no new relevant candidates emerge. Ignore the candidates on the integer declaration line as there is no true dependency among these. This is because the declaration of a variable does not convey how it is going to be used and hence what it is related to. The analysis is now complete (Figure 15-6). Saving the state in a .xfd file, generating a report or creating a .dif file may be done at this time if desired.
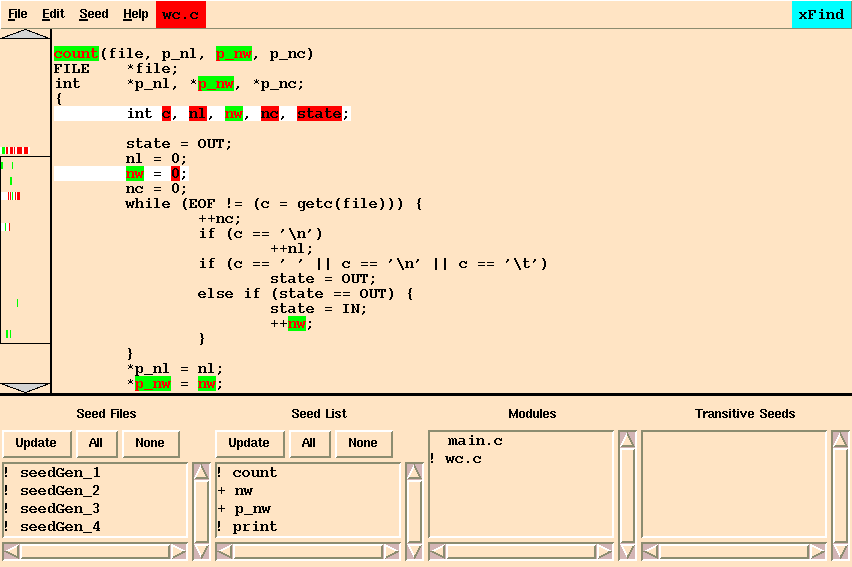 |
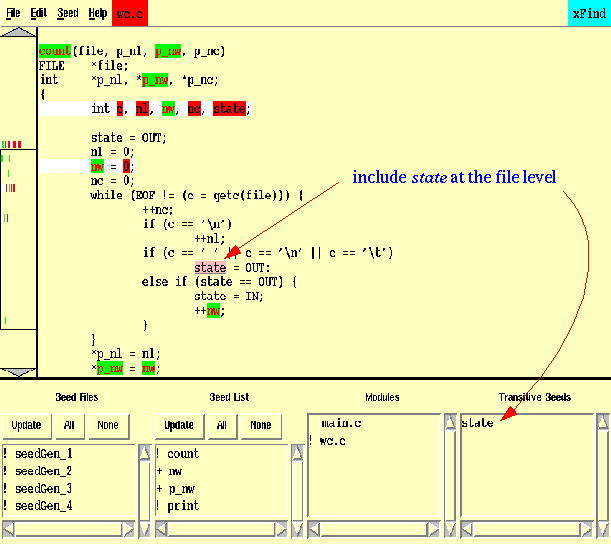
Examination of Figure 15-6 demonstrates one of the limitations of static analysis. The integer variable ``state'' (e.g. in the statement ``state = OUT'') was not found by Find but is in fact an atom that contributes to counting words, as the code shows. To include the ``state'' variable from this statement (Figure 15-7) in the analysis, double click it with the left mouse button and select the ``Seed/File'' menu entry.
 |